Im vorigen Blogeintrag SSAS Data Mining – Clustering wurde die prinzipielle Vorgangsweise mittels SQL Server Analysis Data Mining vorgestellt Auf die Data Mining Ziele und Interpretation der Ergebnisse wurde jedoch nur sporadisch eingegangen. Deshalb wird dieses Mal der Fokus auf die Charakteristiken des Datensatzes, deren Aufbereitung, sowie die Evaluierung der Resultate gelegt.
Datensatz
Der zu analysierende Datensatz enthält Zuordnungen von Benutzern zu Gruppen.
Hier zu erwähnen ist, dass die Gruppenzuordnungen von zwei Systemen mit derselben Benutzerbasis zusammengeführt worden sind. Dementsprechend hoch ist die Anzahl an Gruppen, welche möglicherweise redundant vorhanden sind. Daher ist das Ziel mittels Data Mining zu analysieren, welche Gruppen zusammengeführt werden können. Die Datenstruktur ist jedoch für Data Mining ungeeignet, da die Relationen über mehrere Zeilen verteilt sind. Eine Transformation der Daten in folgende Form ist notwendig.
Für jeden Benutzer gibt es nur noch einen Eintrag, und jede Gruppe wird als Spalte dargestellt.
In diesem Blog-Eintrag wird mit Hilfe von SQL Server Analysis Services (SSAS) eine Clustering Aufgabe vorgestellt. Der Fokus wird hier auf das Erstellen eines Modells auf Basis von Beispieldaten sowie die Evaluierung der Tool Funktionalität und Vorgehensweise gesetzt. Auf die detaillierte Interpretation der Daten und Ergebnisse wird verzichtet, da diese den Umfang sprengen würde.
Die Aufgabe besteht darin Muster im Stromverbrauch eines Haushalts zu erkennen. Für dieses Szenario erstellen wir Cluster anhand von Messwerten. Bei SSAS Data Mining stehen dazu zwei, von Microsoft optimierte, Algorithmen zur Verfügung.
Bei der Recherche nach neuen SQL Server Reporting Features liefert leider auch der offizielle Microsoft Blog wenig Neues. Einzig erwähnenswert ist die Eingliederung des Software-Herstellers Forerunner [1], der neue Möglichkeiten bei der Bereitstellung von Standardberichten bieten soll [2].
Interessanterweise wird in einem Spring ’18 Release Overview von Dynamics 365 – der ERP Software von Microsoft – sehr detailliert auf Power BI Erweiterungen eingegangen. Dies jedoch auch sehr gut versteckt auf S. 252 in einem PDF [3].
Um komplexe Strukturen in einer Datenbank abzubilden, sind eine Vielzahl an Verbindungen notwendig welche mit traditionellen Datenbanksystemen mithilfe von Fremdschlüsseln und Mapping Tabellen oft nur mit großem Aufwand abgebildet werden können. Durch die steigende Komplexität werden dadurch Abfragen sehr umständlich bzw. leidet meist auch die Performance darunter.
Wenn Daten sehr viele Beziehungen untereinander besitzen ist eine Graph Datenbank sehr gut geeignet. Microsoft SQL Server 2017 bietet die Möglichkeit in der gewohnten Datenbankumgebung Daten als Graph abzubilden.
Der Datensatz umfasst etwa 30000 Tickets erstellt in einem Zeitraum von 5 Jahren. Ein Ticket wird mittels einer E-Mail erstellt. Jedem Ticket wurde ein Servicetyp zugewiesen, wobei bei ca. 7000 Tickets dieser Servicetyp fehlt. Insgesamt wurden ca. 400 verschiedene Typen verwendet.
Aufbereitung
Eine Klassifizierung mit einer sehr großen Anzahl an verschiedenen Typen ist nicht zielführend. Betrachtet man den Datensatz kann man erkennen, dass einige Servicetypen nur sehr spärlich verwendet wurden. Um die Kategorien einzuschränken, betrachten wir nun nur Typen mit mindestens 200 Einträgen. Dadurch bleiben 17 verschiedene Kategorien bei verbleibenden 22000 Tickets. Ohne die Anzahl der Tickets signifikant zu verringern (ca. 1000 Datensätze) kann so mit einem abgespeckten Klassenspektrum gestartet werden. Als Input wird die E-Mail im Format „<Betreff>: <Inhalt>“ verwendet.
Klassifizierung
LUIS
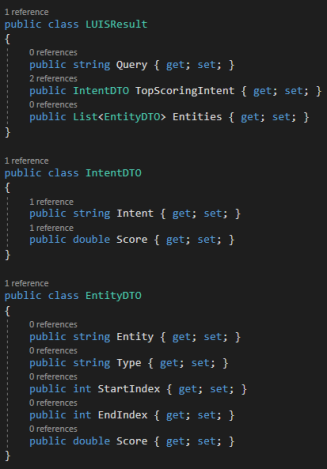
Zur Analyse wird der Cloud Service von Microsoft Language Understanding Intelligent Service (LUIS) verwendet.
Model
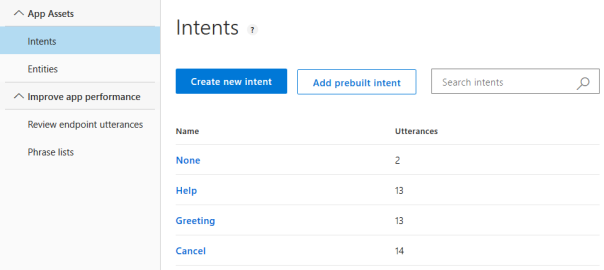
Die Erstellung eines Modells erfolgt mittels Definition von Intents und Entities. Jeder Servicetype wird als Intent abgebildet (siehe Abbildung „Intents“). Als Entities können bei Bedarf beispielsweise Fehlercode oder Personalnummer definiert werden. Auf die genaue Beschreibung zur Erstellung des Modells wird hier nicht eingegangen, da dazu bereits viele Online-Ressourcen verfügbar sind (z.B. https://aischool.microsoft.com/learning-paths/2sBClBrUiwGeeOaAWA2IQ6).
Intents
Batch Testing Panel
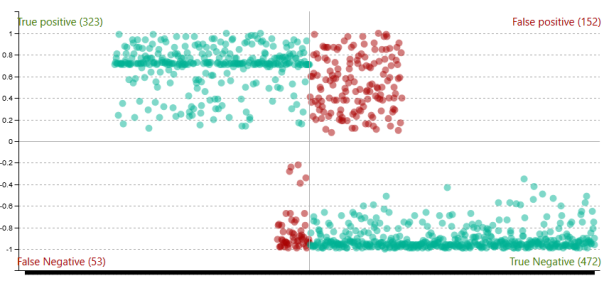
Im Online Portal gibt es die Möglichkeit das trainierte Model zu testen. Für jede Kategorie wird ein Diagramm mit detaillierten Klassifizierungsergebnissen angezeigt (siehe Abbildung „Klassifizierungsergebnis“). Die zugrunde liegenden Testdatensätze können mit einem Klick auf einen bestimmten Datenpunkt bzw. mittels Auswahl von einem der vier Bereiche (TP, FP, FN, TN) angezeigt werden.
Klassifizierungsergebnis
Weiters werden die Kennzahlen Precision, Recall & F-Measure berechnet.
Limitierungen
Maximal 1000 Einträge pro Testdatensatz
Maximal 500 Zeichen pro Textinput
Maximal 10 Testdatensätze
Evaluierung
Beim Testen des Modells (1000 Einträge) wurden nur 12,9 % aller Einträge richtig klassifiziert. Um die Ursache für dieses schlechte Ergebnis zu finden werden die Ergebnisse im Detail zu betrachten. Hier kann man erkennen, dass einige Servicetypen bereits sehr gut erkannt wurden, andere jedoch extrem schlecht.
Servicetyp
Recall
PC
0.03
Schnittstelle Vertriebssystem / ERP System
0.06
Handy
0.06
Laserbeschriftung
0.08
E-Mail (Exchange)
0.09
Telefon (Standgerät)
0.18
DMS
0.30
Drucker (Netzwerk)
0.31
Vertriebssystem
0.34
Notebook
0.43
BI
0.47
Smartphone
0.56
Active Directory
0.59
Druckmanagement
0.62
Telefonanlage
0.62
Office
0.64
ERP System
0.86
Um zu erkennen, welche falschen Kategorien für einen bestimmten Typ am häufigsten zugewiesen wurden, empfiehlt es sich, einzelne Testdatensätze mit jeweils einem Typ zu erstellen.
Dabei lassen sich folgende Erkenntnisse für die problematischen Servicetypen gewinnen:
PC
Dieser Servicetyp ist sehr allgemein, da sowohl Hardware als auch Software (Installationen, Probleme) betroffen sein kann.
Lösungsansatz: Unterteilung in spezifischere Kategorien (z.B. Softwareinstallation, Hardware, etc.)
Schnittstelle Vertriebssystem / ERP System
Fast alle Einträge des Testdatensatzes wurden zu ERP System zugewiesen.
Lösungsansatz: Kategorie entfernen und mit ERP System zusammenführen
Handy
Hier werden die Testtickets vor allem der Kategorie Smartphone zugewiesen. Generell fällt auf, dass es im Bereich Telefonie sehr viele Servicetypen gibt.
Lösungsansatz: Handy, Telefon (Standgerät), Smartphone, Telefonanlage zur Kategorie Telefonie zusammenführen
Laserbeschriftung
Bei vielen Servicetickets handelt es sich um Dateifreigaben und dadurch werden diese der Kategorie Active Directory zugewiesen.
Lösungsansatz: Überarbeitung der Datensatzeinträge und Neuzuweisung zu Active Directory, falls es sich um File/Ordner Freigaben handelt. Dadurch kann sich der Servicetyp Laserbeschriftung um programmspezifische Tickets kümmern.
E-Mail (Exchange)
Hier kommt es unter anderem zu Konflikten mit dem Servicetyp Office, da Outlook in beiden Kategorien sehr häufig erwähnt wird.
Lösungsansatz: Dieses Verhalten ist nur schwer zu vermeiden, da selbst bei manuellem Kategorisieren oft Unklarheiten auftreten. Da ein Fehlkategorisieren jedoch hier unkritisch ist, kann dies so belassen werden.
Das Erstellen eines guten Modells für eine Klassifizierung erfordert viel Fingerspitzengefühl. Mithilfe von einem Testdatensatz kann das Modell im Detail untersucht und schrittweise verbessert werden um ein zufriedenstellendes Ergebnis zu erreichen.
Automatisierung
Nachdem das Modell fertiggestellt wurde, kann dieses im Onlineportal als Webservice zu Verfügung gestellt werden. Neue Servicetickets können nun mithilfe eines SSIS Packages automatisch kategorisiert werden. Hierfür wird als erstes ein Datenflusstask erstellt (siehe Abbildung „Datenflusstask“).
Datenflusstask
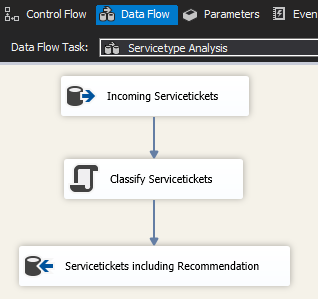
Der Datenfluss setzt sich zusammen aus der Datenquelle mit den neuen Servicetickets, einem Skripttask, welcher den Klassifizierungsservice aufruft, und dem abschließenden Abspeichern der Klassifizierungsergebnisse (siehe Abbildung „Datenfluss“).
Datenfluss
Im Skripttask werden als Eingangsspalten „Betreff“ und „Inhalt“ des E-Mails verwendet. Als Ausgang wird die vom Webservice mit der höchsten Wahrscheinlichkeit deklarierte Klasse zurückgegeben (siehe Abbildung „Skript“).
Skript
Um das vom Webservice gelieferte JSON Objekt zu verarbeiten, wurden Hilfsklassen, welche eine äquivalente Struktur aufweisen, angelegt. Dadurch kann das JSON Objekt zu einem C# Objekt deserialisiert werden (siehe Abbildung „Hilfsklassen“).
In diesem Beitrag wurde gezeigt wie mit LUIS und SSIS mit nur wenigen Zeilen Code eine vollständige Automatisierung für die Klassifizierung von Servicetickets realisiert werden kann. LUIS bietet eine Plattform um auch ohne Expertenwissen ein Machine Learning Modell erzeugen zu können, jedoch ist das Ergebnis des Services stark abhängig von einem guten Design des Modells, welches oftmals erst mithilfe eines iterativen Verbesserungsprozesses zum gewünschten Resultat führt.
Mit Visual Studio 2017 gibt es viele neue Features, die uns als SW-Entwickler das Leben um ein Vielfaches einfacher gestalten.
Leider wurde die Verwendung von lokalen Reports – sog. RDLC Reports – sehr kompliziert gestaltet.
Damit man trotzdem auch mit VS2017 die gewohnten, sehr guten Featuren von RDLC nutzen kann, folgende Anleitung mit Links auf die offiziellen Microsoft Seiten.
Vorgehensweise
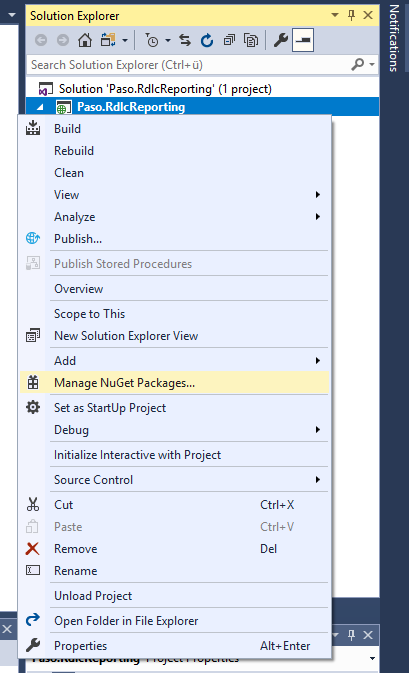
Für die Verwendung von RDLC Reports in Visual Studio 2017 in ASP.NET-Projekten gehen Sie wie folgt vor (eine ähnliche Vorgehensweise gilt auch für die Verwendung von RDLC Reports in Windows-Forms-Projekten):
Schließen Sie alle gerade geöffneten Visual Studio-Fenster
Installieren Sie die Visual Studio-Extension “Microsoft Reports for Visual Studio”:
Download-Link: https://marketplace.visualstudio.com/items?itemName=ProBITools.MicrosoftReportProjectsforVisualStudio
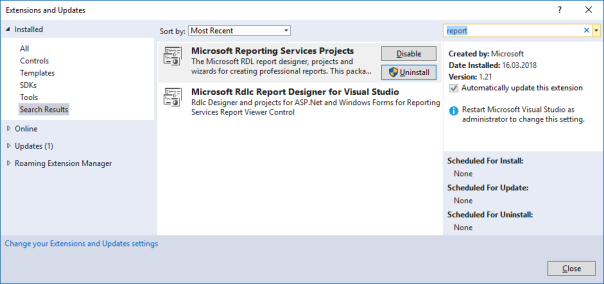
Anmerkung: Falls die Installation der heruntergeladenen vsix-Dateien (Microsoft.RdlcDesigner.vsix und Microsoft.DataTools.ReportingServices.vsix) nicht funktioniert, können die Extensions auch direkt in Visual Studio über Tools > Extensions and Updates installiert werden:
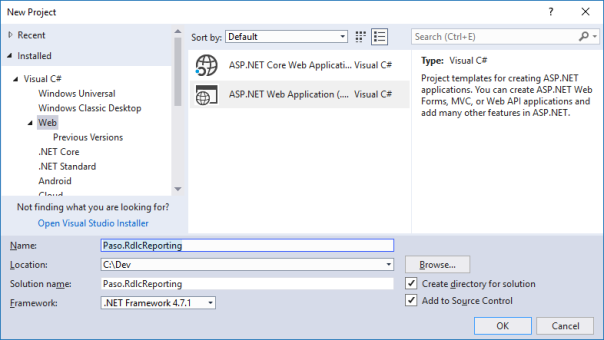
Starten Sie Visual Studio und erstellen Sie eine ASP.NET Web Application:
Alternativ dazu können Sie an einem bestehenden Projekt vom Typ ASP.NET Web Application weiterarbeiten.
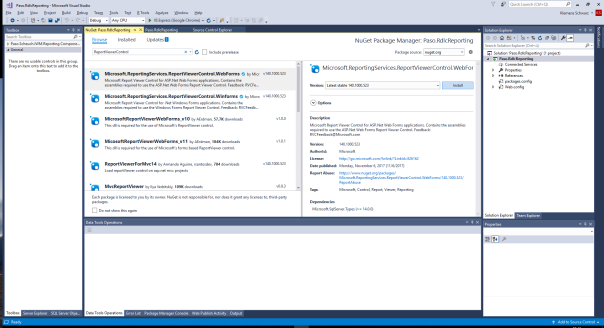
Fügen Sie das NuGet-Package „Microsoft.ReportingServices.ReportViewerControl.WebForms“ hinzu (aktuellste Version zum Zeitpunkt der Erstellung des Blogeintrags: Version 140.1000.523 vom 6. November 2017):
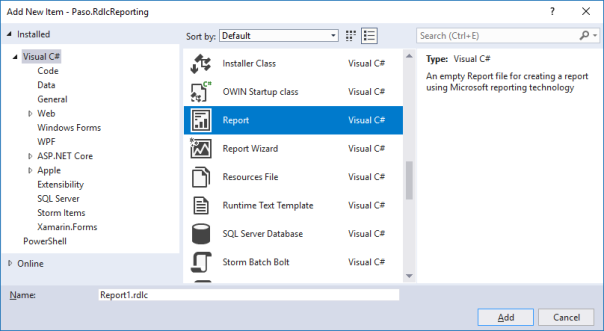
Im Dialog “Add New Item” (Projekt > Add > New Item…) sehen Sie nun unter Visual C# die beiden Einträge “Report” und “Report Wizard”. Wählen Sie “Report” und drücken Sie den Add-Button:
Bestätigen Sie den Dialog, der nach dem Hinzufügen erscheint: Hinweis: Jede weitere Report-Datei können Sie nun über das Projektmenü Add > Report hinzufügen:
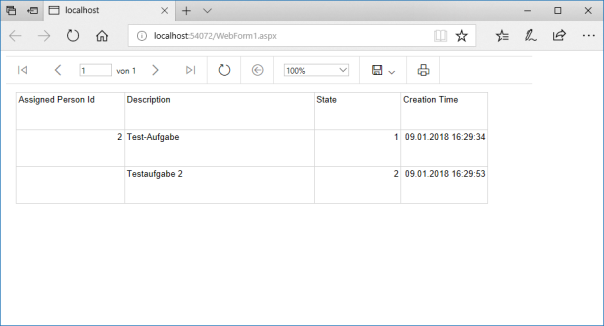
Befüllen Sie den Report:
Öffnen Sie die Toolbox und fügen Sie die gewünschten Report Items hinzu, z.B. ein Table-Objekt:
Nach dem Hinzufügen müssen Sie das DataSet konfigurieren und dafür zuerst eine Datenverbindung zu einer Datenbank hinzufügen sowie die gewünschten Datenbank-Objekte auswählen:
Wählen Sie die gewünschten Datenbank-Objekte aus:
Bestätigen Sie den finalen Dialog mit OK:
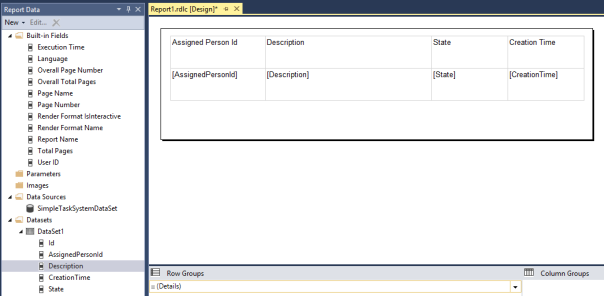
Wechseln Sie von der Toolbox zum Fenster “Report Data” und fügen Sie die gewünschten Reportdaten zum Report hinzu (Beispiel: befüllen Sie die Tabelle mittels Drag&Drop mit den Daten aus dem Bereich “Report Data”):
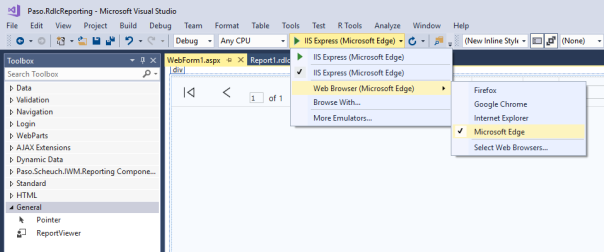
Erstellen Sie eine neue WebForm und fügen Sie den erstellten Report zum Formular hinzu (Project > Add > WebForm):
Wechseln Sie auf die Designansicht
Fügen Sie aus der Toolbox den ScriptManager hinzu (Toolbox > AJAX Extensions > ScriptManager):
Fügen Sie aus der Toolbox den ReportViewer hinzu und ändern Sie ggf. seine Größe:
Falls dieser nicht vorhanden ist, gehen sie wie folgt vor:
In manchen Szenarien ist eine klassische ETL-Lösung mit mehreren Staging/Harmonisierungs-Ebenen nicht realisierbar.
Häufig ist der Grund dafür der Wunsch nach sehr kurzen Latenzzeiten: Damit ist jene Verzögerungszeit gemeint, um Daten vom Vorsystem ins analytische Reporting zu transferieren.
Bei einem Full-Load werden aber die Daten vorher komplett aus der Zieltabelle gelöscht, um diese danach mit den neuesten Daten aus dem Vorsystem erneut zu befüllen.
Die Latenzzeit zwischen Löschen und fertiger Befüllung ist für das Reporting leider problematisch, da keine Daten verfügbar sind.
Um diese Anforderung so gut wie möglich zu bedienen, kommt die „Table-Switching“-ETL-Methode zum Einsatz.
Die Eckpunkte der Lösung:
Es gibt für jede Reporting-Tabelle zwei Tabellen:
Die originale Tabelle (data.Table), auf die das Reporting abzielt
Die Input-Layer-Tabelle (data.Table_in), in welche die Daten transferiert werden
Der Full-Load aus dem Vorsystem erfolgt immer in die Input-Layer-Tabelle
Wenn alle Input-Layer-Tabellen befüllt sind, dann werden diese 3-stufig auf die originale Tabelle mit dem T-SQL Statement „sp_rename“ umbenannt
Zuerst die Input-Layer-Tabelle (data.Table_in) in eine temporäre Tabelle (data.Table_tmp)
Dann die originale Tabelle (data.Table) zu (data.Table_in)
Dann die temporäre Tabelle wieder zur originalen Tabelle
Das Umbenennen geht innerhalb von Millisekunden, wodurch sichergestellt ist, dass nahezu immer Daten für das Reporting vorhanden sind
Um das Befüllen noch schneller zu gestalten, können auch Indices behandelt werden
Vor dem Laden in die Input-Tabellen werden dort die Indices deaktiviert (alter index idx on data.table disabled)
Wenn alle Umbenennungen fertig sind, werden die Indices auf den originalen Tabellen wieder reaktiviert (alter index idx on data.table rebuild)
Das Microsoft Bot Framework mitsamt dem Bot Builder SDK, das für C# und Node.js verfügbar ist, bietet das Rüstzeug zum Senden und Empfangen von Nachrichten sowie eine Anbindung an verschiedene Chat Kanäle wie Facebook oder Skype. Weiters erleichtert es durch die Bereitstellung bereits vorgefertigter Hilfsklassen die Verwendung der Microsoft Cognitive Services.
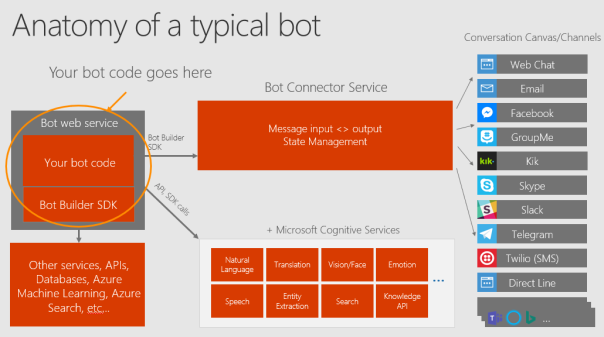
Eine Übersicht über das Microsoft Bot Framework und dessen Schnittstellen ist in Abbildung 1 zu sehen.
Abbildung 1: Microsoft Bot Framework und dessen Schnittstellen
Bei den Microsoft Cognitive Services sind vor allem der QnA Maker sowie die Language Understanding Intelligent Services (LUIS) für die Bot-Kommunikation sehr hilfreich.
QnA Maker
Für die Erstellung eines neuen QnA Maker Services gibt es verschiedene Möglichkeiten. Die Knowledge Base kann erzeugt werden durch:
Die Angabe einer FAQ Website
Das Hochladen von FAQ Dokumenten
Die manuelle Eingabe der Frage Antwort Einträge
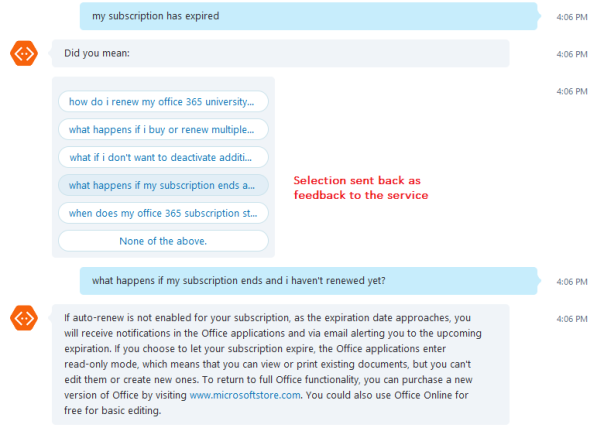
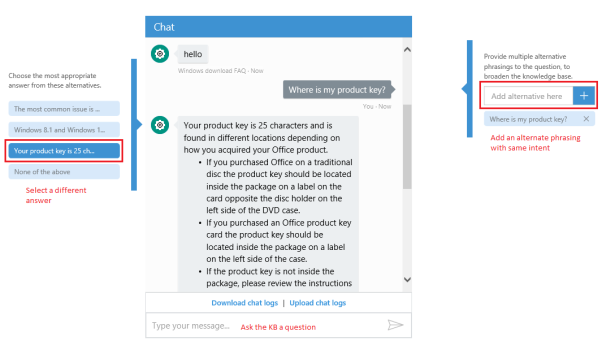
Mit der Knowledge-Base als Startpunkt können dann bei Bedarf Verbesserungen vorgenommen werden. Gibt ein Benutzer beispielsweise eine Frage ein, die nicht hinterlegt ist, werden die wahrscheinlichsten Alternativen zur Auswahl zurückgegeben. Wird eine dieser Alternativen vom Benutzer ausgewählt, erhält das System ein Feedback, welches zur Verbesserung beitragen kann. Ein Beispiel für diese Vorschläge ist in Abbildung 2 dargestellt.
Abbildung 2: Alternativen bei unbekannter Frage
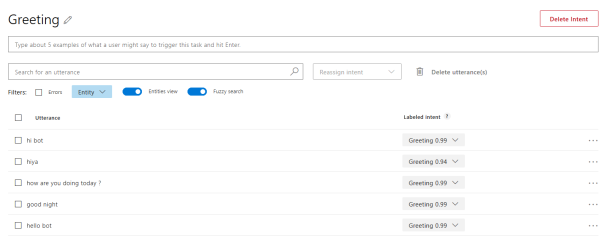
Eine weitere Möglichkeit zur Verbesserung ist es, den Bot zu trainieren. Hierbei kann man die besten Antworten auswählen und auch alternative Phrasen zu einer bestimmten Frage hinzufügen. Ein Beispiel hierfür ist in Abbildung 3 dargestellt.
Abbildung 3: Training eines Bots
Weiters können alle bestehenden Konversationen abgefragt und die Fragen sortiert nach Häufigkeit trainiert werden.
LUIS
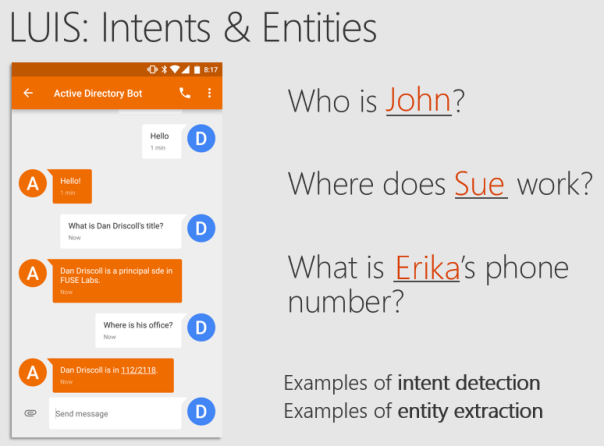
Dieser Service analysiert die Bedeutung (Intent) und die dazugehörigen Objekte (Entities) von verschiedenen Aussagen. Abbildung 4 zeigt ein Beispiel, das die Bedeutung der Fragen (Intent) zu einer gewissen Person (Entity) behandelt.
Abbildung 4: Intents und Entities
Abbildung 5 zeigt, wie mit Hilfe des LUIS Service Portals Intents erzeugt werden können.
Abbildung 5: Intent anlegen
Mit Hilfe dieser Trainingsdaten wird im nächsten Schritt eine bestimmte Wahrscheinlichkeit zugewiesen (siehe Labeled Intent in Abbildung 6).
Abbildung 6: Zugewiesene Wahrscheinlichkeiten
Das dabei erstellte Model kann danach für neue (auch unbekannte) Nachrichten die Wahrscheinlichkeiten berechnen.
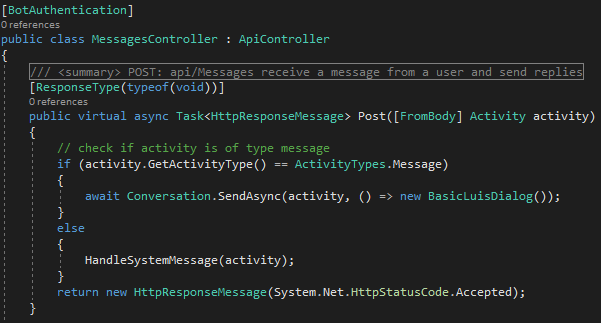
Ist das Model fertig kann LUIS nun in der Bot-Implementierung verwendet werden. Als Einstiegspunkt bei jedem Bot dient der Messages Controller. Dieser ist in Abbildung 7 ersichtlich. Der Message Controller bekommt ein Activity Objekt übergeben. Ist das Activity Objekt vom Typ Message dann wird der LuisDialog aufgerufen. Andere Typen sind beispielsweise das Hinzufügen eines Chatteilnehmers oder das Beenden einer Konversation, auf welche wir hier nicht weiter eingehen.
Abbildung 7: Messages Controller
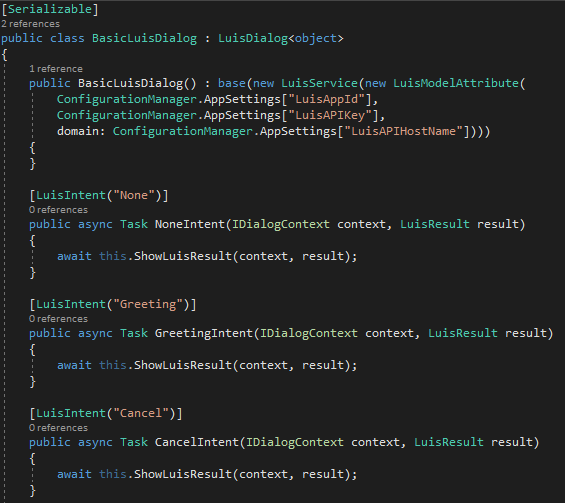
Die Nachricht wird dann über die REST Schnittstelle analysiert und je nachdem, welcher Intent am wahrscheinlichsten ist, wird der dazugehörige Task ausgeführt und eine entsprechende Rückmeldung an den Benutzer gesendet (siehe Abbildung 8).
Abbildung 8: LuisDialog
Auch bei LUIS kann das Model stetig verbessert werden, indem bisherige Zuweisungen bei Bedarf korrigiert werden.
Microsoft AI ist eine Sammlung von Services, Bibliotheken & Tools spezialisiert auf den Bereich der künstlichen Intelligenz. Die Plattform beinhaltet einfach zu verwendende, bereits vollständig konfigurierte Services sowie Tools mit denen komplexe, applikationsspezifische Modelle realisiert werden können. Microsoft AI kann in drei große Gruppen unterteilt werden:
Cognitive Services
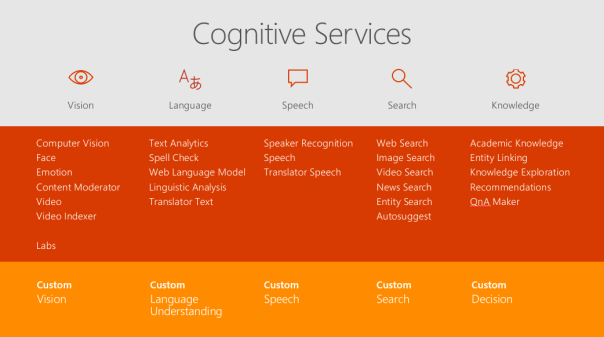
In dieser Gruppe befinden sich vor allem Services, die die Mensch-Maschine-Kommunikation in verschiedenster Weise ermöglichen. Die Cognitive Services sind einfach zu verwenden und werden über REST Schnittstellen zur Verfügung gestellt. Die Integration kann meist mit sehr wenigen Codezeilen realisiert werden. Außerdem werden auch einige konfigurierbare Services angeboten. Ein Überblick über die verfügbaren Module ist in Abbildung „Verfügbare Module im Überblick“ zu sehen.
Abbildung: Verfügbare Module im Überblick
Azure Machine Learning
Eine Unterkategorie von AI ist das sogenannte Machine Learning. Die Azure Machine Learning Workbench bietet eine umfangreiche Umgebung mit einer Vielzahl an Tools zur Anwendung von gängigen Machine Learning Algorithmen. Außerdem verfügt das Programm über viele unterstützende Funktionen zur Vorbereitung der Daten sowie zum Veröffentlichen der erzeugten Modelle. Die Workbench kann auf dem lokalen Computer installiert werden und muss mit einer Azure Ressource verknüpft sein (siehe Abbildung „Azure Machine Learning“).
Abbildung: Azure Machine Learning
Cognitive Toolkit
Deep Learning wird mit Hilfe des Cognitive Toolkits ermöglicht. Verschiedene Arten von Neuronalen Netzwerken können erstellt, trainiert und getestet werden. Durch eine Vielzahl an Konfigurationsmöglichkeiten kann eine hohe Präzision bei Vorhersagen mittels Neuronalen Netzwerken erreicht werden.
Ausblick
In den kommenden Wochen folgen weitere Blogeinträge zum Thema Microsoft AI, in denen auf ausgewählte Themenbereiche vertiefend eingegangen wird. Unter anderem wird gezeigt, wie mit Hilfe künstlicher Intelligenz ein Bot programmiert werden kann.
Master Data Services – kurz MDM – ist ein Bestandteil der SQL Server Produktpalette seit SQL Server 2008 R2 und hat sich in den letzten Jahren bis 2016 nur marginal weiterentwickelt. Dies lag vorwiegend daran, dass Microsoft den Schwerpunkt auf den Business Intelligence Stack gelegt hatte.
Mit dem Release von SQL Server 2017 wurde MDM grundlegend erneuert: HTML5 und neue Technologien tragen zu Stabilität und Akzeptanz bei.
Am Namen und der damit verbundenen, hohen Erwartungshaltung wurde (leider) nichts geändert: was dem Thema an sich zwar nicht schadet, aber für Erklärungsbedarf sorgt.
Was ist MDM und was sind die Herausforderungen, die damit gelöst werden sollen?
In der reinen Theorie ist MDM eine Grundsatzentscheidung dafür, seine Unternehmensdaten zentral zu verwalten, zu vereinheitlichen und dadurch die Grundlage für belastbare Aussagen/Auswertungen zu schaffen.
Auch 2017 sind Unternehmen noch immer damit konfrontiert, Daten aus einer Vielzahl von Systemen zu verwalten. Ist-Daten aus System A wollen in einer Auswertung mit Plan-Daten aus System B angereichert werden. Eine Verknüpfung ist meist aufwändig bzw. gar nicht möglich, da die Datensätze zwar logisch ident sind, aber aufgrund der Schreibweise trotzdem unterschiedlich sind (z.B. Halle8 <> Halle 08).
MDM Systemlösungen
Zur Umsetzung von MDM gibt es bereits viele Produkte: SQL Server, MUM, inubit, SAP MDM, Biztalk, etc. Viele davon bieten einen vordefinierten Bausatz an Funktionen, um sich dem Thema zu nähern.
Eine Standardlösung, ohne jegliche Zusatzprogrammierung, ist aber weder mit Produkt A noch mit Produkt B realistisch – auch wenn das gerne postuliert wird.
Die hohe Kunst im Bändigen von MDM besteht darin, die Verflechtung von organisatorischen und IT-technischen Aktivitäten a) bestmöglich zu koordinieren und b) ein Tool zu verwenden, das die Abläufe und Datenflüsse bestmöglich visualisiert und beim Bearbeiten von Dateninkonsistenzen unterstützt.
Eine optimale MDM-Lösung ist ein Zusammenspiel aus Systemkomponenten (IT) und organisatorischen Verantwortlichkeiten (Fachbereich), bei dem nicht das IT-Tool im Vordergrund steht. Vielmehr ist das Bewusstsein für ein integratives, workflowbasiertes „Doing“ zu beachten.
MDM Projektansatz bei PASO Solutions
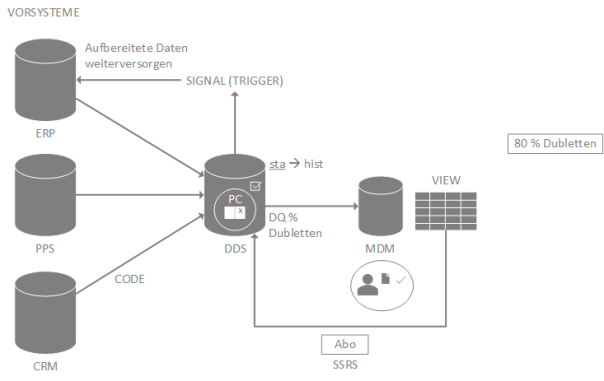
Ein Ansatz, den wir bei PASO Solutions in MDM-Projekten bereits erfolgreich umsetzen konnten, wird in folgender Architekturskizze beleuchtet.
Vorsysteme tauschen Daten über eine sog. Datendrehscheibe – kurz DDS – aus, welche in der Regel als relationale Datenbank realisiert wird. Dadurch ist gewährleistet, dass die Daten mittels SQL-basierten Tools abgelegt und analysiert werden können. Auch dateibasierte Schnittstellen (z.B. XML) können mittels EAI-Tools (vgl. inubit, BizTalk) in die DDS überführt werden.
In der DDS gibt es ein mehrstufiges System zur Datenqualitätsabsicherung. Dazu werden die Rohdaten zuerst in einem sog. Staging-Bereich gesammelt. Neuartige, noch nicht validierte Datensätze werden vom Staging-Bereich in den MDM-Bereich transferiert. Sie haben somit den Status DATEN_UNGEPRÜFT.
Im MDM-Bereich erfolgt die klassische Validierung, insb. auf Dubletten und Inkonsistenzen. Dazu werden Standardalgorithmen wie bspw. Fuzzy-Logic und sog. Mapping-Tabellen herangezogen, um Datensätze zu identifizieren und in unterschiedliche Problemklassen einzuteilen. Der neue Status ist nun DATEN_KLASSIFIZIERT.
Mittels automatisierter Berichte (vgl. SSRS-Abonnements) ist es möglich, Dateninkonsistenzen periodische an sog. Clearing-Stellen zu berichten. Solche Prüfberichte können mittels HTML-Links in webbasierte MDM-Systeme verbinden, um den Korrektur-Ablauf für die Benutzer bestmöglich zu gewährleisten.
Manuell nachbearbeitete Datensätze werden vom MDM zurück an die DDS geliefert und überführen die Datensätze in den nächsten Datenqualitätsstatus DATEN_VALIDIERT.
Über eine konfigurierbare Signal-Funktion werden von der DDS die validierten Daten an andere Systeme weitergeleitet (Trigger-basiert).
Architekturskizze
Vorteile durch MDM mittels Microsoft SQL Server Stack
Microsoft SQL Server bietet neben der klassischen relationalen Datenbank viele weitere Services out-of-the-box. Neben den bekannten Themen wie Analysis Services (SSAS), Reporting Services (SSRS) und Integration Service (SSIS) drängen nun verstärkt die neuen, exotischen Services in den Vordergrund:
Machine-learning Services (vormals R-Services) und Master-Data-Services bilden im Verbund mit den tradierten Services ein optimales Toolset, um den MDM Projektansatz umsetzen zu können.
Mittels MDM können im Clearing-Center durch Machine-learning-Services vorvalidierte Datensätze nachbearbeitet werden, um dann mittels Integration Services zwischen den Datenqualitätsstufen transferiert zu werden.
Alles aus einer Hand, mit einem Toolset und zu einem lukrativen Preis, insbesondere dann, wenn Microsoft-SQL-Server-Lizenzen bereits vorhanden sind, nahezu kostenfrei.
Conclusio
MDM Services von Microsoft ist eine Komponente, um MDM erfolgreich umzusetzen. Aber erst das Zusammenspiel des kompletten SQL Server Stacks ermöglicht eine umfassende und integrative Behandlung des Themas. Organisatorische Rahmenbedingungen (Clearing-Stelle) und Workflow-basierte Abarbeitung sind das A und O, um die Komplexität zu beherrschen.





 Download-Link:
Download-Link: