In diesem Artikel geht es um einen automatisierten Weg, um von einem oder mehreren ASP.NET WebApi Controllern zu einem entsprechenden Client zu kommen. Der Client kann in einer beliebigen Sprache generiert werden, solange es ein Tool dafür gibt.
Vorerst noch eine Anmerkung: Wenn man mit .NET arbeitet, muss das Target-Framework bei mindestens 4.5.1 liegen, um die hier genannten Tools verwenden zu können.
Client generieren in Visual Studio
Anzumerken ist, dass Visual Studio mittlerweile eine native Integration für Swagger Spezifikationen hat. Um in VS einen REST Client zu generieren muss man nur ein neues Projekt erstellen, anschließend mittels Rechtsklick auf das Projekt das Kontextmenü öffnen und dann „Add->REST API Client…“ auswählen. Nachdem man das Metadata File bzw. die Url dazu eingetragen hat, muss man nur noch auf OK klicken und schon startet der Prozess (Standardmäßig muss zur WebService-URL nur „/swagger/docs/v1“ angefügt werden).

UPDATE: Bei der Verwendung von VS2015 kommt es zu einer Inkompatibilität mit Xamarin.iOS, weil die mitgelieferte AutoRest.exe zu alt ist.
Als Workaround verwenden wir stattdessen immer die neueste Version der NuGet-Pakete AutoRest und Microsoft.Rest.ClientRuntime und generieren den Client über die Kommandozeile. Zur Vereinfachung haben wir ein Powershell Skript erstellt, das einfach über die NuGet Package Manager Console ausgeführt werden kann: Tools->NuGet Package Manager->PackageManagerConsole
Zuerst muss das Skript ins Rootverzeichnis des Projektes kopiert werden. Das Skript nimmt zwei Argumente:
- Swagger Url
- Client Namespace
Beispiel.: ./autorest -swagger_url http://swaggertest.azurewebsites.net/swagger/docs/v1 -namespace SwaggerTest
Anschließend muss der Client noch in das Projekt inkludiert werden, das geht am einfachsten so:
- Project->Show All Files
- Der Ordner scheint im Portable Projekt auf mit dem Namen: [namespace]Client
- Rechtsklick auf diesen Ordner->Include In Project
Swagger Spezifikation generieren in Visual Studio
Aber wie kommt man nun zur besagten Spezifikation? Dafür gibt es vielerlei Möglichkeiten, z.B. den Swagger Editor auf Swagger.io. Empfehlenswert ist es allerdings ein natives Tool zu verwenden, in unserem Fall verwenden wir das NuGet Paket NSwag.CodeGeneration, das eine Middleware darstellt und das Swagger File direkt am Webserver vom Code aus generiert. Dafür müssen allerdings noch Annotationen eingefügt werden und ein bisschen Code, der das File generiert. Ein gutes Tutorial vom Entwickler selbst befindet sich z.B. hier: https://github.com/NSwag/NSwag/wiki/WebApiToSwaggerGenerator
UPDATE: Mittlerweile verwenden wir ein anderes Tool zum Generieren der Swagger Spec, das komplett auf Annotationen verzichtet und sich alle nötigen Informationen direkt aus den Web-Method-Headern und Controllernamen holt. Das besagte Tool heißt Swashbuckle, kann einfach über NuGet installiert werden und kommt ohne jegliche Konfiguration aus.
Allerdings gibt es einige Dinge, die man bei der Verwendung von Swagger und Swashbuckle beachten muss, hier eine Liste von Problemen, die bei uns bis jetzt aufgetreten sind:
Generelle Fehlersuche
Um zu Überprüfen, ob das Swagger-File (JSON File) korrekt generiert wurde, startet man den Debug-Modus und geht auf die angegebene localhost URL (falls das Browserfenster nicht automatisch aufgeht, kann man die URL herausfinden, indem man in der Taskleiste auf das IIS-Symbol rechtsklickt und dann WebService auswählt). Dann nach der URL fügt man die Route „/swagger/docs/v1“ hinzu. Kommt nun ein JSON-File, hat die Generierung funktioniert, ansonsten kommt eine Fehlermeldung. Wichtig: Wenn man den WebService bereits auf Azure gepublished hat, dann wird keine Fehlermeldung angezeigt, sondern nur „An error occured“, was zum Debuggen ziemlich nutzlos ist.
Unter der Route „/swagger“ ist eine GUI zu finden, in der alle Methoden aufgelistet werden und die sogar gewisse Funktionalitäten hat, den Web Service durchzutesten. Dieses Interface dürfte allerdings noch in einer sehr frühen Entwicklungsphase sein, weil bei unserem Web Service der Browsertab einfach einfriert, wenn man auf diese Seite geht (Unter Chrome).
Controller mit mehreren Methoden mit der gleichen HttpMethod (Get, Put, …)
Da WebApi 2 das Überladen von Funktionen unterstützt, Swagger aber (noch) nicht, kommt es hierbei zu Problemen.
Es gibt dafür zwei uns bekannte Lösungen:
- Alle Methoden einzigartig benennen (z.B. GetRecipeById, GetAllRecipes, ..) und auf Überladung verzichten.
- Für jede überladene Methode eine eigene Route konfigurieren (über die Annotation [Route(„…“)], z.B. [Route(„id“], [Route(„all“)], wobei in diesem Fall ein RoutePrefix für den Controller definiert werden sollte). Mehr Infos: Attribute Routing
Rekursive Verweise
Da dieser Punkt sowieso bei der Verwendung von JSON auch beachtet werden muss, gehe ich hier nicht näher darauf ein. Grundsätzlich müssen hierfür sogenannte Data Transfer Objects (kurz DTOs) erstellt werden. Nähere Informationen finden Sie auf: DTOs erstellen.
Interne Klassen werden auch von Swashbuckle erfasst
Man möchte natürlich nur die notwendigen Klassen (DTOs, Controller) und Web-Methoden in der Swagger Spezifikation haben und alle anderen ignorieren.
Gerade bei der Verwendung des Entity Frameworks ist das sehr lästig, wenn beim Client alle Model-Klassen zu finden sind, die im Client aber absolut nichts zu suchen haben.
Grundsätzlich erfasst Swashbuckle nur Methoden und Klassen, die als public deklariert sind. Um die Visibility nun nicht zu sehr einschränken zu müssen, kann man statt public das Keyword internal verwenden. Am besten macht man das im Designer durch Öffnen des .edmx-Files, um zu verhindern, dass die protection modifier bei jedem Update wieder auf public geändert werden.
Dazu klickt man zuerst auf den leeren Bereich neben den Tabellen und ändert unter den Properties das Feld „Entity Container Access“ auf „Internal“ um.

Anschließend muss man noch auf jeden Tabellentitel klicken und dort das Feld „Access“ ebenfalls auf „Internal“ umändern.

Danach kann es noch passieren, dass ein paar Build-Errors entstehen, hier muss man einfach alle public-Schlüsselwörter ebenfalls auf internal umändern. Deshalb ist es wichtig, diesen Schritt gleich am Anfang vorzunehmen.
Wenn dennoch Konflikte entstehen, weil man das Datenbank-Modell beispielsweise in einem anderen Projekt innerhalb der selben Solution abgekapselt hat, kann man in der Datei „AssemblyInfo.cs“ in den Properties einfach die Zeile „[assembly: InternalsVisibleTo(„*WebServiceProjektName*“)]“ hinzufügen.
Namenskonflikt von Web Methoden und Tabellennamen
Dieses Problem sollte sich bei der Erstellung von DTOs vermeiden lassen, passiert dennoch ein Fehler bei der Client-Generierung (das Swagger-File selbst dürfte korrekt sein, aber im Visual Studio kommt dann der Fehler beim Importieren), dann hilft es, den ControllerKlassen einen anderen Namen zu vergeben, als den DTO-Objekten.
Unterstriche in Methodennamen
Wer darauf Wert legt, den vollständigen Methodennamen vom Web Service auch im Client zu haben, der sollte auf Unterstriche verzichen, da alles nach dem Unterstrich einfach ignoriert wird.
Verwendung des generierten Clients
Nun zur Anwendung des Clients. Hierzu gibt es nicht mehr allzu viel zu sagen, denn die meisten Probleme treten bei der Generierung des Swagger Files auf.
Als Erstes muss man den Client instanziieren, dieser hat den Namen *Namespace*Client, wobei man den Namespace beim Importieren des Clients angibt. Hier ein Beispiel aus einer Xamarin App:
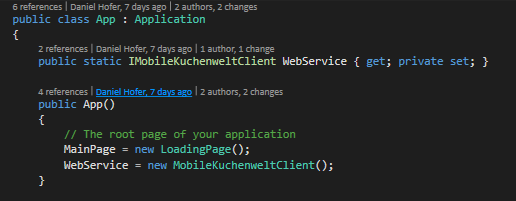
Über diesen Client kann nun auf alle Web Methoden zugegriffen werden, hierbei ist allerdings zu beachten die Extension-Methods zu verwenden und nicht die Async-Methoden, also kurz gesagt: Die Methode mit dem Namen selben Namen der Web Methode im Controller ist die Richtige, die Methoden, die auf Async enden ist die „kompliziertere“ und muss nur verwendet werden, wenn man die async Funktionalität auch serverseitig implementiert hat bzw. im Client braucht.
Zusammenfassung
Abschließend lässt sich sagen, dass sich der Overhead jedenfalls auszahlt, und zwar noch viel mehr bei größeren Web Services. Swagger ist mittlerweile die Standard-Methode für REST und lässt sich gut vergleichen mit WSDL für SOAP Services.













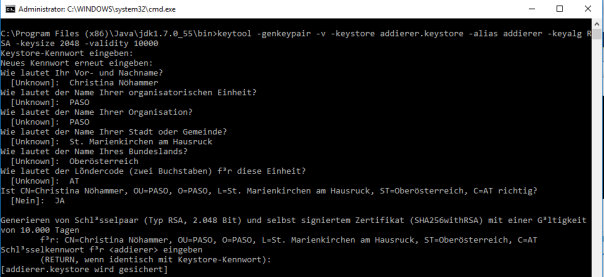

 Man kann die Signierung mit folgendem Befehl überprüfen:
Man kann die Signierung mit folgendem Befehl überprüfen: Wie im Bild oben zu sehen, werden dann die Informationen des Keystores angezeigt.
Wie im Bild oben zu sehen, werden dann die Informationen des Keystores angezeigt.
